Meta Description: With the development of Aiohttp, it's now easier for users to make their own web servers. Read this guide to see how Aiohttp can be used for your own personal and professional projects!
What is Aiohttp?
Aiohttp is an HTTP server/client for asyncio. It allows users to create asynchronous servers and clients. Also, the aiohttp package works for Client WebSockets and Server WebSockets. Here's how you can install Aiohttp via pip.
pip install aiohttp
Now that aiohttp is installed, we’ll start by using an example!
Obtaining a Web page
The documentation from this aiohttp example is used to grab an HTML page. Let’s see how it works:
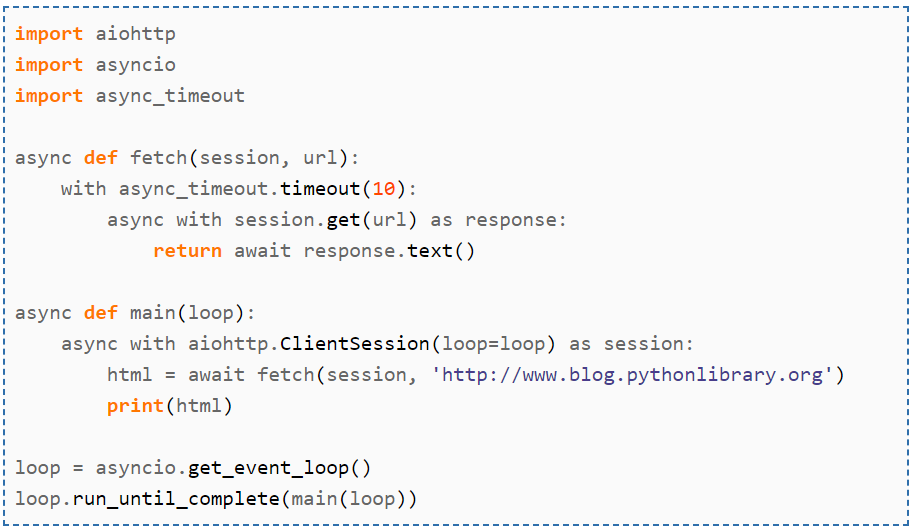
First, we import aiohttp, asyncio, and async_timeout which allows us to timeout a coroutine. Then, we create a loop at the bottom and call it to our main function. It makes a ClientSession object that passes the fetch() function that finds the URL.
Finally, we use the fetch() function to get the URL’s HTML and the timeout feature. If everything works without it timing out, you’ll see a multitude of text spewed right into stdout.
Downloading Files
In this aiohttp example, it shows you how to download one or multiple files. You can download files through a coroutine as well!

You’ll notice a few new items in this example such as async_timeout. This allows you to make a timeout context manager. Let’s read our code from the bottom on the way up. In the bottom, it creates an asynchronous sync loop and uses it as our main function.
We make a Client Session Object in the main function. It creates a coroutine function which gathers the URL of everything we want to download. In download_coroutine, it creates a context manager that runs for about X seconds.
Once that X amount of seconds runs out, the context manager runs out or ends. In this aiohttp example, the timer is on for 10 seconds. Next, we use the session’s get() function which finds us a response object. This is where things start to get interesting.
When you make a content attribute of the response object, it returns aiohttp.StreamReader which allows the user to download the file in whatever size we’d like. Once we read the file, we can write it to our local disk. Lastly, we use the response() function to finish the response that’s processing.
According to the documentation, it calls out the release() implicitly. However, in Python, explicit is better, and there is a note that tells us not to rely on the connection. So its better for us just to release the function to prevent further issues.
There is one section that’s blocking here, and that's the section of code that writes to the disk. By doing this, the code remains blocked. Make sure to use this example when you need to obtain multiple links from a website.
Conclusion
To conclude, learning aiohttp is the best way to improve your workflow and its interesting plan where users don't have to waste time creating a server, downloading links, and writing asynchronous files. Give it some time to learn, and you'll experience a powerful tool that reduces your project making time.
Are there any additional questions, you have for aiohttp?
Share in the comments below. Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â Â
Sources:
https://github.com/aio-libs/aiohttp/tree/master/examples
https://pawelmhm.github.io/asyncio/python/aiohttp/2016/04/22/asyncio-aiohttp.html
Comments will be moderated and
rel="nofollow"will be added to all links. You can wrap your coding with[code][/code]to make use of built-in syntax highlighter.